审核专家:郑远攀
郑州轻工业大学教授
我们上网冲浪,经常会遇到类似下图所示的人机验证流程,需要点选一下其中的方框才能访问网页内容。
reCHAPTCHA 人机验证对话框 来源丨wiki
上述操作流程是为了保护网站安全而设置的验证,毕竟网站的注册、登录、领券、投票等应用场景都存在被机器(程序脚本)刷数据进而而造成各类损失的风险。
但是点一下就知道访问网站的“主体”是不是真人(human being)?这么草率的验证方式真的能区分真人和机器吗?
点选验证码的原理
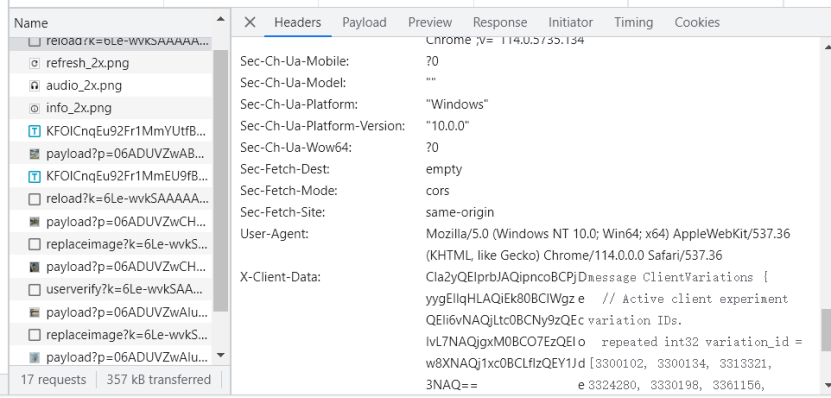
首先让我们来在谷歌浏览器Chrome开发者工具窗口中看看上图所在的部分网站信息。按下键盘上的F12功能键,打开如下图所示的开发者工具窗口之Network Panel(网络面板),点击人机身份验证的按钮,可以看见左侧的网络传输数据包。
网站Chrome开发者工具窗口之Network Panel(网络面板) 来源丨google
也许你还看不懂这些内容的含义,不过没关系,只需要把这些东西看作是本地浏览器发给远程网站服务器的一些数据;这些数据不是给人看的,而是给服务器看的。
服务器通过分析这些“乱码”里的信息可以判断其是一个真人产生的数据还是单纯由自动化程序代码发出的请求数据包,进而可以区分出操作的主体是人还是机器。

Python语言编写的抢课脚本代码 来源丨Bilibili
你以为你只是“开玩笑”一样点选了一下屏幕窗口中的小方块,然后“就进入了后面的网页,但实际上你的操作会生成数据包并被发送到服务器端。
比如当人点击验证码时,其实是发送了一大包加密的数据。被加密的数据大概有以下几种:
>>>>1.用户行为数据:页面停顿时间、点击按钮、鼠标轨迹等;
>>>>2.环境变量:用户设备信息、网络信息、操作系统信息等;
>>>>3.浏览器指纹:包括请求头(headers)信息,ip地址(网卡逻辑地址)信息,MAC地址(网卡物理地址)信息,地理位置信息,cookie信息等。
请求头内容
虽然这种改进的验证方式方便了许多用户,不用再像12306网站那样需要用户痛苦地从一堆图案中选中目标对象物体,但遗憾的是,这种验证和识别类验证码相比,安全性上并没有得到很大提高。
这些数据的加密由前端js代码来完成,js代码可以通过浏览器自带的开发者工具抓包获得。这就说明,理论上可以逆向分析这些代码并找出加密逻辑,进而伪造请求数据。虽然有的js代码会被混淆得难以阅读,但各路大佬们又见招拆招,发明出了反混淆工具,还原js代码。
可以说,这种对抗自从验证码出现以来就从未停止。
验证码的演变过程
验证码的起源可以追溯到1997年,Altavista公司的利利布里奇等程序员为了阻止黑客入侵后台,首创了扭曲字母验证码。

来源丨ifanr
直到现在,这类验证码依然是一些网站的主要验证方式,过于扭曲的字母常常迫使显示器前的人们摇头晃脑,左右扭动地去辨认目标对象。
验证码真正拥有姓名是在2003年,路易斯·冯·安(Luis von Ahn)斯团队在卡内基梅隆大学提出了“验证码(CAPTCHA)”这样一个程序概念。CAPTCHA是英文“Completely Automated Public Turing Test to Tell Computers and Humans Apart”的首字母简写,其中文含义是全自动区分计算机和人类的公开图灵测试。
在CAPTCHA测试中,电脑会自动生成一个问题让使用者来解答,由于机器无法回答出CAPTCHA的问题,所以逻辑反推,能回答出问题的使用者即可视为人类。
随着安全防护与破解入侵两方面抗衡的日益升级,验证码的识别难度在增加,形式也在多样化。从诞生到现在,验证码主要有这几类:短信验证码、语音验证码、图形验证码、问题验证码、滑动点选验证码等等。
>>>>短信验证码
人们可以拿手机查看验证码进行登录操作,而程序/机器人想要进行这种自动化的操作会比较复杂。

来源丨jhkjsms.com
>>>>语音验证码
人类可以接电话听声音,且为了防止语音辨识软件分析声音,语音内容会掺有杂音或者做出一定程度内仍可以被人类接受的变声。
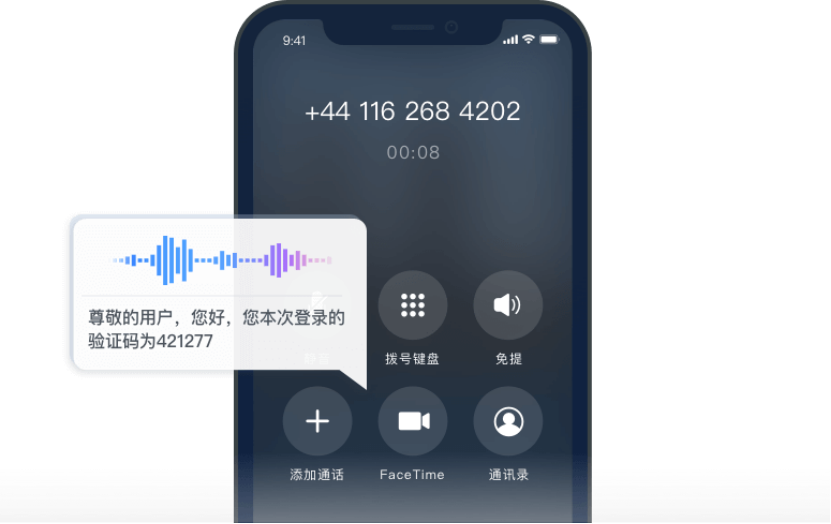
来源丨cloud.juphoon.com
>>>>图形验证码
图像验证会故意模糊中心位置,使用非程序可识别文字来达到防止机器识别的目的;视力障碍人群可选择语音验证方式。
如图,Image Turker 和 Audio Turker分别表示识别图像和语音验证码的人类。authorize.net 图像验证码是最简单的,而 google.com 音频验证码最难。
人类对于图像和语音验证码的识别正确率 来源丨web.stanford.edu
>>>>问题验证码
在国内网站,点选图案的问题验证码通常是最让人崩溃的,一些“猜猜你是谁”的游戏式验证方式,往往让人直接放弃进入下一步。

来源丨
>>>>滑动点选验证码
2014年,Google推出了新的验证码系统 NoCAPTCHA reCAPTCHA,就是我们一开始看到的那种,不需要我们输入验证码,点一下就行。
2018年,Google升级了reCAPTCHA,用户甚至不需要进行操作,系统会在后台分析用户浏览网站的方式,进行风险评分。如果用户评分过低,网站会要求用户进行额外的操作来证明自己是合法用户。
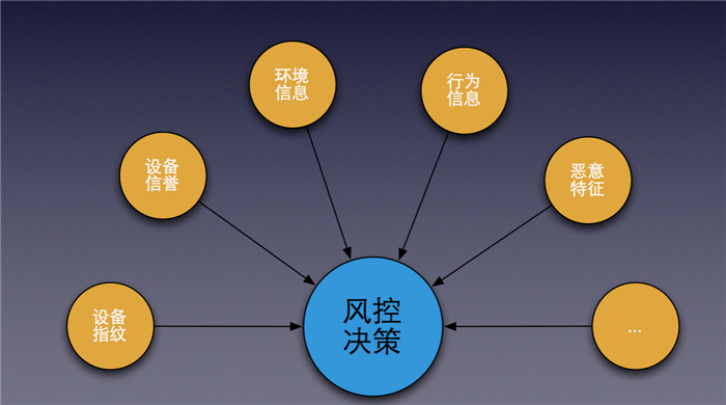
来源丨知乎
国内验证码的特点
在中国比较常见的验证方式都属于无知识型验证码,它有三大优点:用户体验好,风险识别率高,风险拦截能力强。

来源丨B站截图
来源丨百度安全验证
>>>>用户体验好
用户不需要思考,体验相对流畅。
>>>>风险识别率高
随着机器学习的发展,机器具有人类的知识,简单的图形验证码也有被攻破的时候,而无知识型验证码基于人类的行为特征和操作环境来综合评测风险,人类的行为难以被攻击方模仿。
>>>>风险拦截能力强
在后台执行的评判逻辑,判断用户的风险指数,能根据不同程度的可疑操作推送出不同难度的验证码,甚至直接阻断操作,有效进行风险拦截。
看完本文后相信你已对验证码有所了解,也明白我们访问网站时为什么总需要处理那些奇怪的验证码啦。
会员全站资源免费获取,点击查看会员权益
